本节课的主题:
CFG
上一节里我们已经简单介绍了 CFG,也介绍了一个例子 G1,如下左所示。可以发现,G1 中存在两条规则,它们的左值是一样的,所以我们可以使用一种简写形式,如下右所示。
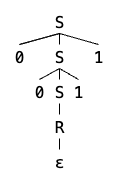
G1:SSR→0S1→R→ϵShorthand:SR→0S1∣R→ϵ
由上下文无关文法生成的语言称为上下文无关语言(Context Free Language, CFL),反过来,有如下定义:
📌定义:A 是一个 CFL,当存在一个 CFG G 使得 A=L(G)。
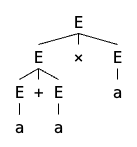
我们可以用一棵树来表示一个字符串的推导过程,下图展示了使用 G1 生成字符串 0011 的过程:
📌定义:一个 CFG G 是一个四元组 (V,Σ,R,S),其中:
- V:变量的有限集合
- Σ:终结符的有限集合
- R:规则的有限集合,规则的形式为 V→(V∪Σ)∗
- S:开始变量的有限集合
下面是几种常用写法:
- u⇒v:表示在 G 中存在一条从 u 到 v 的替换规则
- u⇒∗v:表示 u 可以通过一系列替换规则最终变成 v
- L(G)=w∣w∈Σ∗ and S⇒∗w
以防你疑惑什么叫上下文无关:所谓上下文无关,就是指在生成字符串时,它不需要管前面和后面的字符是什么,只需要不断用替换规则进行替换就行了。而下面这个例子就展示了什么叫上下文有关:
BB1→0B1∣ϵ→1B
这显然不是一个 CFG,关注到第二条规则 B1→1B,它要求当 B 下文出现一个 1 时才能替换,这就是上下文有关了。而 CFG 应当只考虑变量本身。
下面我们来看另一个例子:
G2:ETF→E+T∣T→T×F∣F→(E)∣a
我们可以用 G2 来推导出很多式子,例如 a+a×a,下面是这个式子的解析树(parse tree):
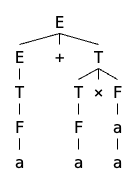
解析树其实蕴含了一些隐藏信息。你可以发现,乘法永远会比加法的优先级更高,因为它的深度更深,计算上肯定是它更先被计算。
我们来对比一下 G2 和 G3:
G2:ETF→E+T∣T→T×F∣F→(E)∣aG3:E→E+E∣E×E∣(E)∣a
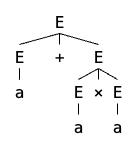
如果你尝试一下的话,就会发现 G2 和 G3 是等价的,它们能识别同一种语言,也就是有 L(G1)=L(G2)。但这是否说明它们没有区别?不是!如果你仔细的话就会发现,G3 是没有优先级的!例如同样是生成 a+a×a,G3 的解析树有两种:
可以看到,在 G3 中,先算加法或先算乘法都是可以的,并没有优先级。我们说,如果一个字符串对应两棵不同的解析树,那么这个 CFG 就是有二义(ambiguous)的。从这两棵树可以看出,G3 是有二义的。在编程语言里,二义性是不允许出现的,任何一门编程语言都需要消除二义性,例如 Python 使用缩进,C 使用花括号。
正则表达式可以转换为 CFG,例如下面这个例子:
0Σ∗1SBSAB→0B1→BB∣0∣1∣ϵ→A1→0B→BB∣0∣1∣ϵ
对于正则表达式 0Σ∗1(Σ=0,1),存在两个与之对应的 CFG,这说明正则表达式与对应的 CFG 不唯一。而且我们能发现,只要我们想,我们总能让规则的右边最多剩下两个变量。例如在上例中,第一个 CFG 的第一条规则 S→0B1 的右边存在三个变量,而通过将 0B 单独提出来用另一个中间变量 A 来替代,就让右边只剩下了 A1 两个变量。
需要注意的是,虽然正则表达式都可以转换为 CFG(也可以说所有正则语言都可以用 CFG 表示),但并不是 CFG 生成的语言都是正则语言。这一点也证明了 CFG 是比正则表达式更强大的模型。
PDA
既然正则表达式对应的更强大的模型是 CFG,那么 FA 呢?是否存在一个自动机和 CFG 一样强大?有的兄弟,有的,隆重介绍下推自动机(Pushdown Automata, PDA)。
PDA 类似于 NFA,但要比 NFA 多一个外置装置——下推栈(Pushdown Stack)。PDA 每走一步,可以做以下操作:
PDA 可以用这个栈来存储额外信息,以此来决定当前要不要转移,要转移到哪里,因此 PDA 要比一般的 FA 更加强大。
📌定义:一个 PDA 由一个六元组 (Q,Σ,Γ,δ,q0,F) 定义,其中:
-
Q:状态集
-
Σ:输入的字符集
-
Γ:栈的字符集
-
δ:Q×Σϵ×Γϵ→P(Q×Γϵ)
例:δ(q,a,c)=(r1,d),(r2,e)
-
q0:初始状态
-
F:接受状态集
回忆我们之前讨论的语言 D=0k1k∣k≥0,我们证明过它是非正则的,FA 无法无限计数,因此 FA 无法表达它,但 PDA 不一样。我们可以用 PDA 的栈来进行计数,具体的操作是:
- 每次读到 0,就压入栈,直到读到 1;
- 每次读到 1,就从栈顶推出一个 0;
- 输入结束时,如果栈为空,进入接受状态。
再来考虑 B=wwR∣w∈0,1∗(wR 表示 w 的反转字符串),这里我们需要使用到 PDA 的非确定性,我们这样使用栈:
- 应用非确定性,每次可以选择以下其中一种操作:
- 读入字符并压入栈;
- 读入字符,并将其与栈顶字符比较,如果不一样就拒绝;
- 输入结束时,如果栈为空, 进入接受状态。
非确定性再结合栈,这赋予了 PDA 作弊般的表达能力。比如说,我们可以用 PDA 来识别任何正则表达式所表达的语言。怎么做?在一开始,PDA 一个字符都不读,它只是通过 ϵ-转移进行非确定的状态转移。每次转移,它都通过正则表达式的规则生成字符,并将字符压入栈。结合 PDA 的非确定性,我们可以让 PDA 不断地去尝试构建各种各样的字符串,直到覆盖全部可能的字符串,压入栈中。待生成完成后,开始读入字符,并和栈顶元素进行比较,如果读到最后栈刚刚好为空,进入接受状态;如果没有任何一条路径能接受输入字符串,那就拒绝。
但 PDA 也不是万能的,例如语言 ww∣w∈0,1∗,PDA 无法表达它,这一点我们之后会证明,然后引出另一种全能的模型。
CFG→PDA
CFG 和 PDA 其实是等价的,接下来我们将会学习两者的相互转换。
📜定理:如果 A 是一个 CFL,那么存在某个 PDA 能识别它。
证明上述定理的思路,就是把 A 对应的 CFG 转换成 PDA。但是怎么做?你可能会觉得棘手的是选择哪条规则进行替换,但其实这一点可以用非确定性解决。真正有难度的部分在于如何跟踪中间结果,那这部分就是栈的工作。PDA 依赖非确定性去猜测使用哪条规则进行替换,使用栈保存中间结果,待栈中只剩下终结符,去比较栈中内容与输入字符串是否相等,相等就进入接受状态,不相等就拒绝。
这件事说起来很简单,但做起来会有一些微妙的问题。我们说使用栈来记录中间状态,意思是指记录推导过程。我们以 G2 为例,回忆一下推导 a+a×a 的过程,我们可以预见栈中内容的变化过程为:
E⇒E+T⇒T+T×F⇒F+F×a⇒a+a×a
但是这里存在一个问题:栈只允许对栈顶进行操作,我们无法直接操作栈顶以下的字符。好在这个问题是可以解决的:我们每次只替换栈顶的变量,一旦栈顶的变量变成终结符,我们就立马把它从栈顶弹出去和输入字符串进行匹配,匹配成功后,继续替换栈中的剩余变量。通过这种方式,我们无需违反栈的性质就能完成替换。
按照这样的思路,我们将从 CFG 转换为 PDA 的步骤总结如下:
- 将开始变量压入栈顶;
- 如果栈顶是:
- 变量:使用规则替换;
- 终结符:弹出,然后与下一个输入字符进行匹配;
- 当栈为空时,接受。
以 G2 为例,假设输入字符串为 a+a×a,下面将是栈中字符变化的过程:
E⇒E+T⇒F+T⇒T+T⇒a+T⇒ pop +T⇒ pop T⇒T×F⇒F×F⇒a×F⇒ pop ×F⇒ pop F⇒a⇒ pop ∅
总结
📜定理:A 是一个 CFL,当且仅当存在某个 PDA 能识别 A。
这条定理比上一条要更强,它说明了 PDA 和 CFG 是完全等价的。我们已经证明了 CFG ⇒ PDA,但我们将不会去证明 PDA ⇒ CFG,因为这个证明会有点复杂,并不作为课程要求,如果有兴趣可以自行了解。
最后总结一下我们已经学习过的几种模型以及它们之间的关系。
FA 包括 DFA、NFA、GNFA,它们都能识别正则语言,我们称之为正则语言的识别器(recognizers);而 PDA 能识别 CFL,我们称之为 CFL 的识别器。正则表达式能生成正则语言,我们称之为正则语言的生成器(generators);而 CFG 能生成 CFL,我们称之为 CFL 的生成器。
正则语言是一种 CFL,CFL 包括了正则语言,因为 PDA 比 FA 要更加强大,肯定能识别正则语言。
尽管我们说 PDA 比 FA 更强,但其实这几类模型都属于弱模型,这里存在一些其他它们无法识别的语言。在下一节,我们将介绍强模型,这将是贯穿我们剩余课程的主题,也是这门课的重点。虽然这些弱模型的表达能力不足,但学习它们有助于我们理解语言,为学习图灵机做好铺垫。
课后题
A. 令 E=aibj∣i=j and 2i=j,证明 E 是 CFL。
条件 i=j 且 2i=j 意味着在 i,j≥0 的坐标平面上,我们需要避开两条直线:j=i 和 j=2i。
这两条直线将第一象限分成了三个区域:
- 区域 1: j<i (即 a 的数量比 b 多)
- 区域 2: i<j<2i (即 b 的数量在 a 的 1 倍到 2 倍之间,且不等于边界)
- 区域 3: j>2i (即 b 的数量比 a 的两倍还要多)
因此,E=L1∪L2∪L3,其中:
- L1=aibj∣i>j
- L2=aibj∣i<j<2i
- L3=aibj∣j>2i
我们需要为这三个语言分别构造 CFG。
1. 对于 L1=aibj∣i>j
这个语言表示 a 至少比 b 多一个。我们可以先生成相等数量的 a 和 b,然后在左侧添加额外的 a。
S1→aS1b∣aS1∣a
2. 对于 L3=aibj∣j>2i
这个语言表示对于每一个 a 至少对应两个 b,且最后还要多出至少一个 b。
S3→aS3bb∣S3b∣b
3. 对于 L2=aibj∣i<j<2i
这是最关键的部分。条件 i<j<2i 意味着:
- j 必须大于 i(至少包含一对 a→bb)
- j 必须小于 2i(至少包含一对 a→b)
我们可以通过组合“一个 a 匹配一个 b”和“一个 a 匹配两个 b”的规则来构造。为了保证严格不等式,文法必须确保这两种匹配规则都至少被用到一次。文法构造如下:
S2A→aS2b∣aS2bb∣aAbb→aAb∣aAbb∣ab
由于我们已经为 L1,L2,L3 分别构造了上下文无关文法,因此它们都是 CFL。
令 S 为原语言 E 的开始符号,我们可以通过引入以下产生式来合并它们:
S→S1∣S2∣S3
E 对应的完整 CFG:
SS1S2AS3→S1∣S2∣S3→aS1b∣aS1∣a→aS2b∣aS2bb∣aAbb→aAb∣aAbb∣ab→aS3bb∣S3b∣b
由于存在一个 CFG 能识别 E,因此语言 E 是一个上下文无关语言。证毕。