[COMPT 0x06] 图灵机变体/丘奇–图灵论题
上节课我们简单介绍了图灵机。图灵机是通用计算机的模型,我们一般把计算机就看作是一台图灵机。事实上,任何合理的模型都应该具备和图灵机一样的能力,能模拟通用计算机的模型并不止图灵机,那为什么要选择图灵机来讨论?其实模型的选择并不重要,这门课选择图灵机,只是因为它的设计很简洁,相比于其他的模型,例如重写系统、λ-演算等,图灵机更加贴近计算机的运作方式,更容易理解。
这节课,我们将深入了解一下图灵机。我们将会认识几种图灵机的变体,但最后我们会发现,这几种变体其实都是图灵机的不同定义方式,它们本质上是等价的。
本节课的主题:
-
图灵机变体
- 多带图灵机
- 非确定图灵机
- 图灵枚举器
-
丘奇–图灵论题
-
图灵机编码
多带图灵机
📜定理:语言 是图灵可识别的,当且仅当存在一个多带图灵机能识别它。
在讲图灵机的时候,我们想象输入是写在一条纸带上的,就我们接下来要讨论到的概念而言,我们可以称之为单带图灵机(single-tape TM)。而多带图灵机(multi-tape TM),就是指图灵机可以同时操控多条纸带,如下图所示。

直觉上来说,一个模型的装置如果变多,它的能力也应该增强,就例如一个 PDA 如果具有不止一个栈,那么它就能识别更多语言。但可惜,对于图灵机而言并不是这样。多带图灵机和单带图灵机本质上是等价的,可以相互转换。我们简单介绍一下证明思路。
要用单带图灵机模拟多带图灵机,本质上是用一条纸带模拟多条纸带的功能。我们可以将一条纸带分为好几段,这一点可以依靠引入额外符号 # 来进行分隔,每个 # 表示一个分段的结束。对于分段 ,我们向其中写入第 条纸带的内容,并在末尾加上 #。此外,我们还得记录多带图灵机的各个头指针当前的位置,这一点也可以靠引入额外符号来做到:我们令 表示当前头指针停留在字符 上。则对于每个分段 ,必定存在一个位置,该位置上的字符形如 。上述过程可以用下图表示。
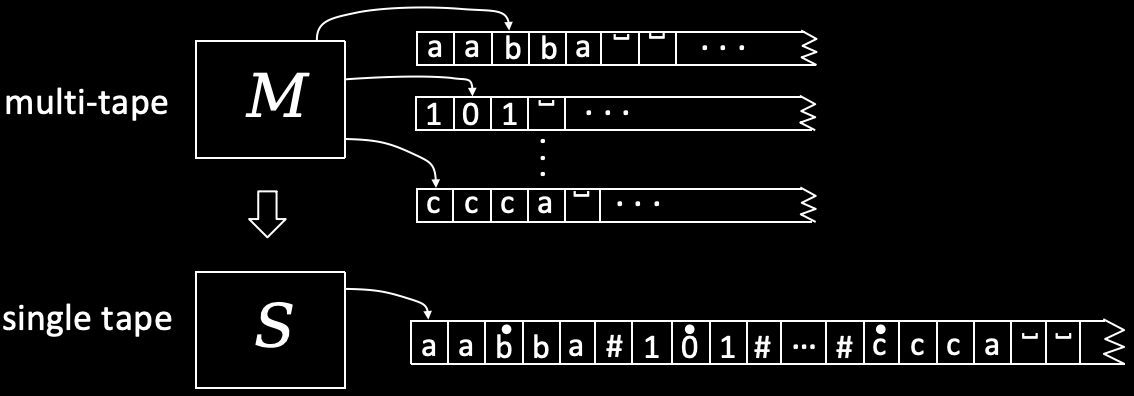
简单来说,我们通过将一个纸带分为多段,每一段模拟一个纸带的功能。需要注意的是,每个分段的长度是有限的,而真正的纸带是无限的。为了处理分段长度不够用的情况,我们设置一个中断,当需要用到更多空间时,我们对分段进行“扩容”,即将后续内容后移。
由此一来,我们能很直观地发现两者完全等价。
非确定图灵机
📜定理:语言 是图灵可识别的,当且仅当存在一个非确定图灵机能识别它。
非确定图灵机(Non-deterministic TM)在普通的图灵机上引入了非确定性,它和确定图灵机(Deterministic TM)的区别仅在于转移函数,其转移函数的右值是一个幂集:,表示可以转移到多种状态。只要 NTM 中存在一条路径能使其接受输入字符串,那就表示它接受了该字符串。同样地,NTM 和 DTM 仍然是等价的。我们下面给出证明思路。
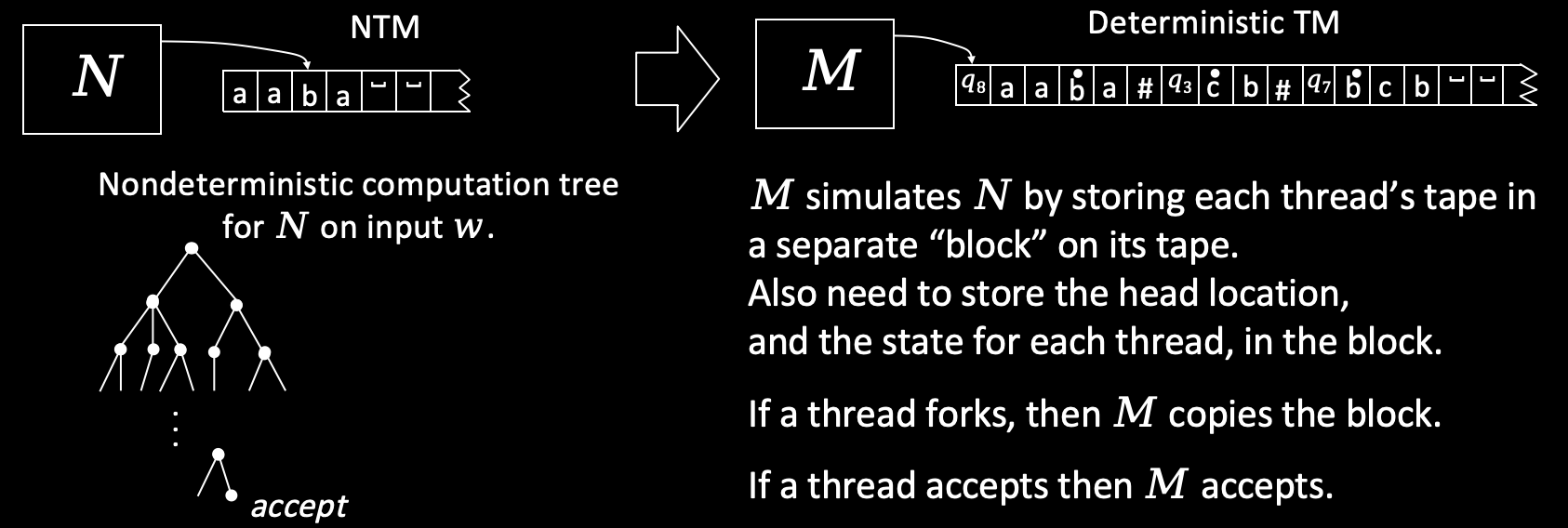
非确定性给予了 NTM “猜测”的能力,因此它会产生分支,这些分支产生不同的并行线程。要使用 DTM 来模拟 NTM,关键在于如何处理这些线程。思路和上面的证明差不多。我们仍然把 DTM 的纸带分为多段,每一段代表一个线程,用 # 分隔。当前头指针在哪,我们就令哪的字符写做 。假设一个线程遇到了分支,那就要产生新的线程,这一过程通过复制原线程中的内容到一个新的分段中来完成,新线程的操作就在这个新的分段中完成。
不过还没结束!注意在多带图灵机中,虽然有多条纸带,但图灵机只有一个,因此全局只有一个状态。但在 NTM 中,每个并行线程都代表图灵机的一次执行,因此每个线程都有一个状态,如果不记录,就会丢失这些状态。为了跟踪每个线程的状态,我们要对每个分段扩展一个状态位(例如在每段开头进行扩展),状态位上的符号 代表线程当前所处的状态。整体如下图所示。
图灵枚举器
📜定理:语言 是图灵可识别的,当且仅当存在一个图灵枚举器 ,使得 。
图灵枚举器(Turing Enumerator,TE)是一种生成器,就跟正则表达式、上下文无关文法一样,它用于生成字符串。
它和图灵机不一样的地方在于,它没有输入,因此它的纸带在一开始是空白的;此外,它还有一个外置设备——打印机,TE 就通过打印机进行输出。假设 是一台图灵枚举器,那么它所能表达的语言 就是它用打印机能打印出的所有字符串的集合,写做 。
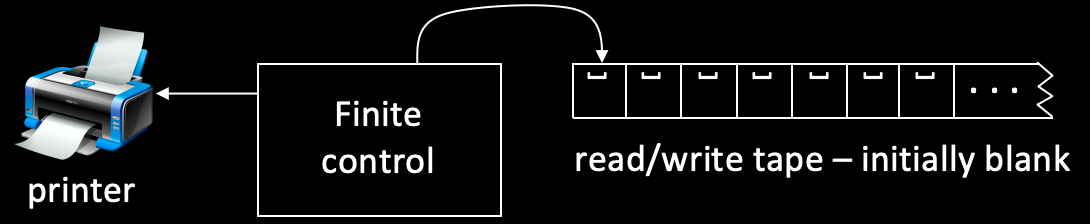
TE 在一种规则的指导下,使用纸带记录状态,使用打印机输出字符串。至于 TE 具体是如何工作的,这一点我们在此不去细究,我们只是讨论 TE 和 TM 的等价性。跟此前的证明不太一样,此前的证明中,至少有一个方向是显然成立的,因此我们没有去讨论。而这里,我们需要从两个方向上去讨论等价性。
我们先证明 TE TM。对于图灵枚举器 ,我们构造这样一台与之等价的图灵机 :对于一个输入字符串 ,并让 去不断生成字符串 ,比较 是否与 ,如果相等则接受,如果不相等就继续这一过程。显然, 与 是等价的,并且 要么接受然后停机,要么以不断循环的方式来拒绝。
再证明 TM TE。对于图灵机 ,我们构造这样一台与之等价的图灵枚举器 : 生成 ,然后将 输入 ,如果 接受了 ,则打印 ,并去生成 ,重复上述过程。这个构造看起来没问题,但是忽略了一个情况:要是 在输入 上无法停机怎么办?这会导致 被卡在某个地方,无法继续推进。
这里我们必须引入并行性,即将所有 并行输入给 ,而不是顺序输入。我们的做法是: 每次在 上运行 步( 从 1 开始递增)。这样的做法实质上是一种有界的批处理,每一轮选取 个输入运行 步,若 步内有字符串被接受,则让 将其输出,被拒绝的,则进入 轮继续运行。由于每一轮都会有新的字符串 ,并且运行步数也会增加,这样就保证了 不会被卡住。
在 的构造中,我们会发现, 输出字符串的顺序取决于 处理输入字符串 的速度,而不是字符串的字典序。那有没有办法让 按字典序输出字符串?其实是有的,前提是语言 是可判定的。如果对这一点感兴趣,可以自己尝试证明。
丘奇-图灵论题
虽然在今天的人们看来,算法和图灵机的等价性似乎是理所应当,但在 20 世纪初,这两个概念其实没有任何联系。直到 1936 年丘奇(Alonzo Church)证明了任何“可有效计算”的东西都可以用 λ-演算表达;而几乎同一时间,图灵(Alan Turing)提出了图灵机模型,并证明任何“可有效计算”的过程,都能由图灵机完成。而后数学家们又发现 λ-演算与图灵机的计算能力是等价的,也就是说一个模型能解决的问题,另一个模型也能解决,算法这一直觉上的概念和图灵机这一形式化的定义之间才架起了桥梁。至此,丘奇-图灵论题(Church–Turing thesis)形成了,它的核心表述是“一切在直觉意义上可由算法计算的东西,都能够被图灵机(等价:λ-演算等形式系统)计算。”
1900 年,德国数学家大卫·希尔伯特在巴黎举行的第二届国际数学家大会上所作题为《数学问题》的演讲中提出了 23 个最重要的数学问题。其中第十个问题为:
Give an algorithm for solving Diophantine equations.
丢番图方程(Diophantine equations)是未知数只能使用整数的整数系数多项式等式,其形式为:
我们可以用语言 来形式化地描述丢番图方程的解。
1970 年,Matiyasevich 使用图灵机模型,证明了这个问题是不可判定的,不存在多项式时间内的算法能解决丢番图方程,即 不是图灵可判定语言。丘奇-图灵论题为这个问题的解决起到了奠基的作用。
不过值得注意的是, 虽然不是图灵可判定的,但却是图灵可识别的。
图灵机编码
我们说图灵机能处理很多问题,就比如上面提到的丢番图方程。这些问题的输入具有很多形式,可以是方程、图、状态机,甚至是另一个图灵机。而图灵机的输入只能是字符串,这里就涉及到对输入对象的编码(encoding)问题,即把一个对象转换成一个字符串。下面我们介绍一下编码的符号表示。
假设 是一个输入对象,我们使用 表示 的字符串编码;假设 ,,…, 是一个输入对象的列表,那么我们使用 表示这些对象被共同编码为一个字符串。
虽然我们不打算在这里详细去说到底如何编码,但我们可以简单讨论一下:直接将两个字符串对象 和 拼接在一起得到 的编码方式是否妥当?这其实是不妥的,因为 无法被逆向还原为 和 ,我们不知道在哪里分开 和 ,这会导致二义性。
那么如何描述一个图灵机?其实我们可以直接使用 high-level 的自然语言来进行描述,大致形式为:
我们曾经构造过一个图灵机 来识别语言 ,我们以 为例,展示一下如何描述一个图灵机:
总而言之,high-level 的描述没有问题,我们无需在意纸带、状态等的管理。
课后题
带左重置的图灵机(A Turing machine with left reset)与标准图灵机类似,但转移函数的形式如下:
如果有 ,那么,当机器处于状态 时读入 ,会使得机器的头指针在写入 之后跳转到纸带的开头,并进入状态 。注意这种图灵机不像标准图灵机一样,能一个字符一个字符地向左移动头指针。证明带左重置的图灵机所能识别的语言类和图灵可识别语言是同一类语言。
要从两个方向进行证明:
带左重置的图灵机 标准图灵机
标准图灵机的头指针可以随意左右移动,因此可以模拟带左重置的图灵机:
- 遇到 就右移一格;
- 遇到 就不断左移直到回到最左端。
因此带左重置的图灵机能识别的语言一定是图灵可识别的。
标准图灵机 带左重置的图灵机
要用带左重置的图灵机模拟标准图灵机,难点在于左移操作。我们使用打点的方式标记头指针当前所指的位置,例如 ,左移就是找到 的前一格,如何做?
这里给出一种很简单的思路——整体右移。还记得在证明多带图灵机与单带图灵机等价的时候,我们用到了这种右移。由于带左重置的图灵机的右移操作并不受限,所以实现整体右移是完全可行的。右移的时候,我们将所有字符都复制到下一格去,但维持标记不变。比如 的前一格字符为 ,那么右移之后, 变成 ,即 继承了 的标记。右移完成后,从最左端(此时最左端变成了纸带的第二格)开始向右扫描,哪里有标记,哪里就是我们要找的位置。这样就实现了标准图灵机的左移操作。
证明一个语言是图灵可判定的,当且仅当存在一个图灵枚举器能按字典序枚举这个语言。
我们先来证明存在一个能按字典序枚举语言 的枚举器 是图灵可判定的。我们构造这样一个图灵机 :令 不断生成字符串 ,对于每一个生成的 ,都拿来跟输入字符串 进行比较,如果 ,那么就接受 ;否则,我们再去比较 和 字典序,倘若 ,那么就代表 不可被接受,拒绝 ;否则,继续让 去生成下一个字符串。上述算法可以概括为:
bool turingMachine(string x) {
while (w = E(Σ*)) {
if (w == x) return accept;
else if (w > x) return reject;
}
}显然,对于任意输入字符串 , 永远是可以停机的, 要么被接受,要么待 生成一个字典序大于 的字符串时被拒绝。
下面证明 是图灵可判定的 存在一个能按字典序枚举语言 的枚举器 。首先假设 的字符集为 ,那么 包含了全部 的字符串。由于 是图灵可判定的,那么一定存在一个图灵机 ,它能在所有 的字符串下停机。于是,我们可以构造这样一个 :对于所有 ,每次取 输入进 ( 已经按字典序从小到大排序),并且只允许 最多执行 步, 步之内,如果 接受了 ,那就说明 ,准备打印;否则,令 ,重复这一流程。由于 是图灵可判定的,只要生成的 , 肯定能停机,因此,随着 不断增大,最终所有字符串肯定都能在有限时间内被拒绝或接受,任何属于 的字符串肯定都会被 接受。 只需要将每一轮被 接受的字符串按下标顺序进行打印,就实现了按字典序枚举语言 了。