本节课的主题:
上节课,我们已经说明了假如一个语言是 CFL,当且仅当存在某个 PDA 能识别它。下面是两个推论:
- 每个正则语言都是 CFL。
- 如果 A 是 CFL,B 是正则语言,那么 A∩B 是 CFL。
第一条推论在上一节课已经提过,我们来理解一下第二条。这其实蛮好理解的,PDA 是一个带有栈的 FA,正则语言只需要 FA 就能识别,所以 PDA 自然能识别正则语言和 CFL 的相交部分,因此 A∩B 肯定能被 PDA 识别。
但是,假设 A 和 B 都是 CFL,那么 A∩B 是否是 CFL 呢?答案是不一定。PDA 用栈来模拟 CFL,如果 A∩B 是 CFL,那么就存在一个 PDA 能同时模拟 A 和 B,相当于是用一个栈来模拟两个栈,这一点不一定能做到。也就是说,CFL 在 ∩ 下并不是封闭的。我们将在这节课里证明这一点。
虽然 CFL 在 ∩ 下不是封闭的,但它在 ∪,∘,∗ 下是封闭的。
CFL 的泵引理
在这一节,我们将尝试去证明一个语言不是 CFL。我们证明一个语言不是正则语言时,使用的是泵引理,我们在这里仍将使用泵引理,不过要换成适用于 CFL 的版本。
📜泵引理(CFL 版):对于任意 CFL A,存在一个 p 使得如果 s∈A 并且 ∣s∣≥p,那么 s=uvxyz,其中:
- uvixyiz∈A,∀i≥0
- vy=ϵ
- ∣vxy∣≤p
它的意思是,如果语言 A 是 CFL,那么当它的任意字符串的长度大于某个值 p 时,我们可以将这个字符串分成五部分 uvxyz,并且将其中的 v 和 y 重复任意次数,得到的字符串仍然属于 A,前提是 v 和 y 不能同时为空,且 vxy 的长度不能大于 p。
我们将从定性和定量两方面来解释这个引理。先来定性分析。
想象我们有一条很长很长的字符串 s,那么它对应的解析树应当也是很高很高的。CFL 的规则数肯定是有限的,但有限的规则允许生成无限长的字符串,所以让我们把字符串的长度想象成无限长,解析树的高度想象成无限高。根据鸽巢原理,在这棵解析树的一条路径上,肯定有变量出现了不止一次!以下图为例,其中一条路径中,R 出现了两次。
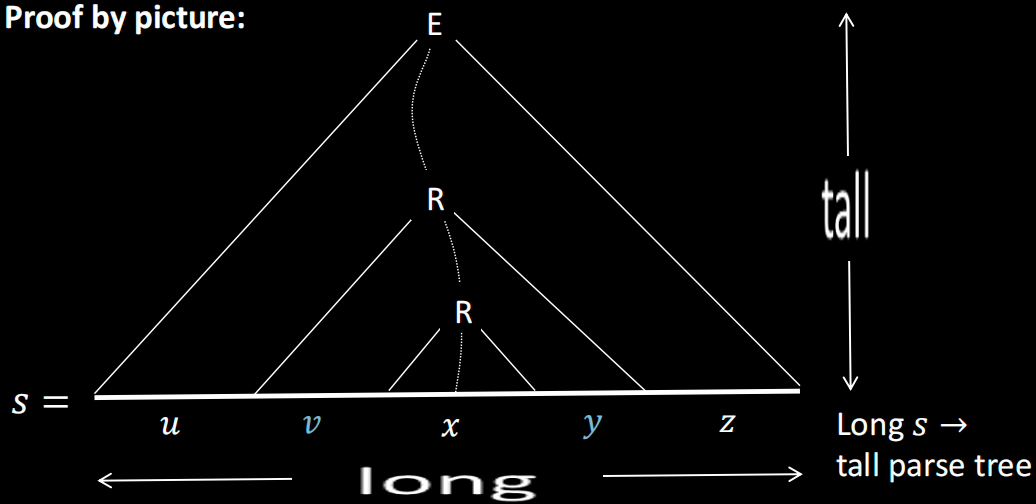
这两个 R 位于同一路径,说明通过替换规则,从 R 出发还能再产生 R,因此,可以想象,如果我们在这两个 R 之间再插入 R,那肯定也是合法的。于是就会得到:
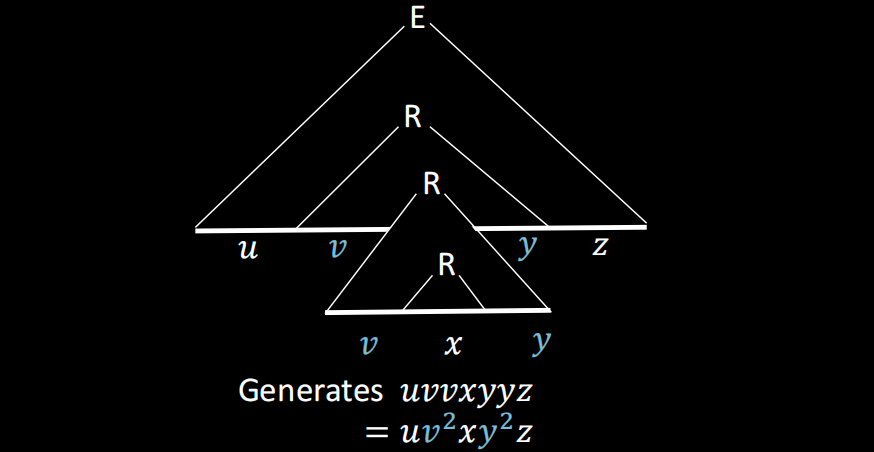
没错!可以看到最下面的那个 R 生成的字符串 x,肯定会被同路径上之前的 R 生成的字符串包裹,把包裹住 x 的左右两边的字符串拆成 v 和 y,只要继续插入 R,v 和 y 就会被重复。因而有了泵引理说述的特性。我们把上面这一证明过程称为“复制粘贴论证(cutting and pasting argument)”。
为从数学角度解释这条引理,我们将进行定量分析。
令 b 为 CFG G 的规则中,最长的右值长度,它也是解析树中节点的最大分支数,比如假设一个 G 中右值最长的规则是 E→E+T,那么 b=3;再令 h 为字符串 s 的解析树的高度,V 为 G 的变量集。那么,字符串 s 的长度 ∣s∣ 最大为 bh。为了保证解析树中某条路径上出现重复的变量,我们需要使 h>∣V∣。因此,我们令 ∣s∣>b∣V∣。我们选取 p 时,是希望解析树中能肯定出现重复变量,以保证字符串 s 中存在可以让我们“泵”的字符串。为此,我们令 p=b∣V∣+1。由鸽巢原理,当 ∣s∣≥p 时,解析树的路径上肯定能出现重复变量。换言之,必定存在一个值 p,使得当 ∣s∣≥p 时,满足上文提到的“复制粘贴”。
经过上述讨论,我们已经理解了泵引理的第一条 uvixyiz∈A,∀i≥0,那么剩余两条呢?
对于第二条 vy=ϵ,我们如何保证 v 和 y 不同时为空?想象这样一种情况:在 CFG 中存在 R→T 和 T→R∣ϵ,这样的话,我们可以让 R 和 T 不停地相互替代,但最终替换为 T 并将 T 替换为 ϵ,使得解析树的某一路径仍能出现重复的 R,但最终 v 和 y 都是空串,从而违反第二条件。为了防止这种事情发生,我们可以施加一个约束,那就是当我们选择解析树时,我们每次都选最小的那棵。什么叫最小?我们刚才所说的情况属于无效替换,它只是不停在两个变量之间循环,最后什么都不生成,显然这些步骤都是可以被化简的,化简之后的解析树仍能生成同样的字符串。我们将那种无法被化简的解析树称为最小解析树,从而防止这种情况发生。因此第二条件成立。
那如何保证 ∣vxy∣≤p 一定成立?可以这样想,当我们选择“泵”,也就是重复变量 R 时,我们总是选择最低(层数最深)的 R 作为泵。由于它本身高度不高,因此很难生成太长的字符串,不会生成超过 p=b∣v∣+1 个叶子节点。因此第三条件成立。
原理可以不用理解,但题一定要会做。接下来让我们用泵引理来证明一个语言不是 CFL。
1. 证明 B=0k1k2k∣k≥0 不是 CFL。
假设 B 是 CFL,令 k=p,则 ∣0p1p2p∣>p。根据泵引理,我们可以把 0p1p2p 分成五部分 uvxyz,由于 ∣vxy∣≤p,因此 vxy 不可能同时包含 0 和 2. 因此,若我们将 v 和 y 复制任意次,比如 2 次得到 uv2xy2z,那么肯定会使字符串中 0,1,2 的个数不想等,因此 uv2xy2z∈/B,从而证明 B 不是 CFL。
2. 证明 F=ww∣w∈Σ∗,Σ=0,1 不是 CFL。
假设 F 是 CFL,考虑字符串 0p1p0p1p,显然有 ∣0p1p0p1p∣≥p。根据泵引理,我们可以把 ∣0p1p0p1p∣≥p 分成五部分 uvxyz,由于 ∣vxy∣≤p,因此 vxy 中不可能同时覆盖两组 0 或 1. 若我们将 v 和 y 复制任意次,比如 2 次得到 uv2xy2z,那么肯定会使字符串中 1 的数量前后不相等,因此 uv2xy2z∈/F,从而证明 F 不是 CFL。
图灵机
到此为止,我们学习的所有模型其实都是有缺陷的模型。作为计算模型而言,它们都是不合格的,但是学习它们有助于我们理解计算模型。可以说此前的内容都只是热身,而现在我们将进入本门课程的正题。
隆重介绍——图灵机(Turing Machine, TM)。图灵机才是真正的通用计算机的模型。它将贯穿我们剩下的课程。在本节课,我们将对它进行一个粗略的介绍,在下一节课,我们再来具体探讨它。
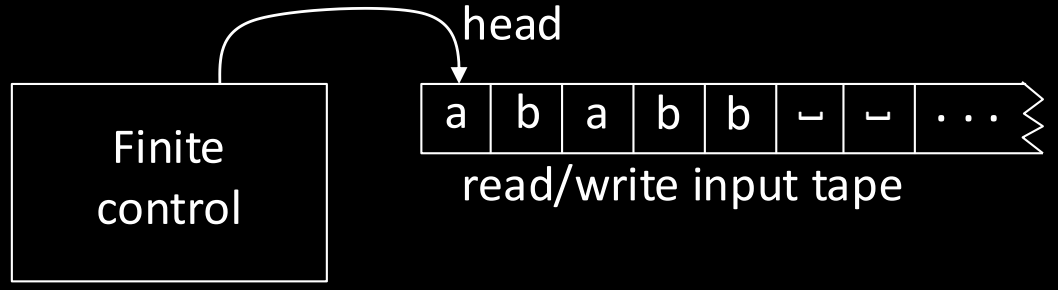
将我们的输入字符串想象成一条纸带。FA 用它的头指针从左到右依次读取纸带上的字符,每读一个字符转换一次状态。PDA 比 FA 多了一个外置的栈,可以用于记录额外的信息,但栈的操作是受限的,因此也有一些它无法表达的语言存在。而 TM 比它们都要强大得多。
TM 的头指针不仅可以读取纸带上的字符,还可以修改以及左右移动,这意味着它随意操作纸带上的字符。并且 TM 的输入纸带是无限延伸的,意思是即使输入字符串读完了,后面也依然有位置可供 TM 使用。此外,不论是 FA 还是 PDA,它们都只有在读完整个字符串之后才能选择拒绝或接受,但 TM 可以在任何时候停机(halt),这比 FA 和 PDA 的效率要高不少。
回到 B=akbkck∣k≥0 这个例子,我们知道它不是 CFL(此前已经证明),让我们来看看 TM 如何能识别它:
- 从左到右扫描一遍输入字符,检查其是否满足 a∗b∗c∗(即 a,b,c 是否顺序出现),如果不是,直接拒绝,否则进入步骤 2;
- 将头指针移回最开始,重新扫描字符串,并且删除遇到的第一个 a、b、c;
- 若扫描结束后,未能完整删除一组 a、b、c,即缺少其中 1 个或 2 个,则拒绝;
- 若完整删除了一组 a、b、c,则重复步骤 3;
- 若已无字符可删除,则接受。
上述算法当然不是最优的,但却是最好理解的。不过,我们如何实现“删除”操作?注意,TM 并不带有“橡皮擦”这种装置,要表示删除,最好的做法就是往字符集中引入额外字符,比如在这个例子中,我们可以引入 a,b,c,用它们分别替换原本的 a、b、c,以此表示删除。
下面我们给出图灵机的形式化定义:
📌定义:图灵机由一个七元组 (Q,Σ,Γ,δ,q0,qacc,qrej) 定义,其中:
- Σ:输入字符集
- Γ:纸带字符集(Σ⊆Γ)。注意恒有 ⎵∈Γ,⎵ 是一个占位符,之前提到 TM 的纸带是无限长的,那么输入字符串之后的位置就是用 ⎵ 占位
- δ:Q×Γ→Q×Γ×R,L (R 表示 Right,L 表示 Left)。举一个例子 δ(q,a)=(r,b,R),它是说当前 TM 到状态为 q,头指针读到字符 a,TM 状态转移到 r,将原本的 a 改写为 b,头指针右移。
- q0:起始状态
- qacc:接受状态
- qrej:拒绝状态
图灵可识别&图灵可判定
一个 TM 可能最终进入三种状态:
- TM 接受了字符串,进入 qacc;
- TM 拒绝了字符串,进入 qrej;
- TM 拒绝了字符串,但一直循环无法停机(rejects by looping)。
📌定义:语言 A 是图灵可识别的(Turing recognizable),如果存在一个图灵机 M 使得 A=L(M)。
📌定义:图灵机 M 是一个判定器,如果 M 总是能停机。
📌定义:语言 A 是图灵可判定的(Turing decidable),如果存在一个图灵判定器 M,使得 A=L(M)。
显然,图灵可判定的要求比图灵可识别要高。一个图灵可识别语言未必总能让图灵机停机,但一个图灵可判定语言一定能被图灵机识别,因此图灵可判定语言肯定是图灵可识别的,但反过来不成立。
课后题
A. 给定文法 (G=(V,\Sigma,R,\langle STMT\rangle)),其中产生式为:
⟨STMT⟩⟨IF_THEN⟩⟨IF_THEN_ELSE⟩⟨ASSIGN⟩→⟨ASSIGN⟩∣⟨IF_THEN⟩∣⟨IF_THEN_ELSE⟩→if condition then ⟨STMT⟩→if condition then ⟨STMT⟩ else ⟨STMT⟩→a:=1
终结符集合:
Σ={if,condition,then,else,a:=1}
非终结符集合:
V={⟨STMT⟩,⟨IF_THEN⟩,⟨IF_THEN_ELSE⟩,⟨ASSIGN⟩}
问题:
- 证明该文法 (G) 是二义的(ambiguous)。
- 给出一个生成同一语言但无二义性的新文法。
1. 要证明一个文法是二义的,那就要去找一个字符串,使得该字符串能对应两棵不同的解析树或推导路径。G 能生成简单的 if-else 结构,思考 C 语言中,如果没有花括号来声明作用域,就会出现二义性,这常常发生在 else 和 if 的匹配上,例如:
if c1 then (if c2 then a:=1 else a:=1)if c1 then (if c2 then a:=1) else a:=1
受到这个例子的启发,我们取串:
w=if condition then if condition then a:=1 else a:=1
也就是 else 既可以和内层 if 配对,也可以和外层 if 配对。下面给出两种不同推导(等价于两棵不同解析树),从而证明二义性。
推导 1:else 与内层 if 配对(外层是 if-then)
⟨STMT⟩⇒⟨IF_THEN⟩⇒if condition then ⟨STMT⟩⇒if condition then ⟨IF_THEN_ELSE⟩⇒if condition then if condition then ⟨STMT⟩ else ⟨STMT⟩⇒if condition then if condition then ⟨ASSIGN⟩ else ⟨ASSIGN⟩⇒if condition then if condition then a:=1 else a:=1
推导 2:else 与外层 if 配对(外层是 if-then-else)
⟨STMT⟩⇒⟨IF_THEN_ELSE⟩⇒if condition then ⟨STMT⟩ else ⟨STMT⟩⇒if condition then ⟨IF_THEN⟩ else ⟨STMT⟩⇒if condition then if condition then ⟨STMT⟩ else ⟨STMT⟩⇒if condition then if condition then ⟨ASSIGN⟩ else ⟨ASSIGN⟩⇒if condition then if condition then a:=1 else a:=1
同一个串 (w) 有两棵不同语解析树(两种不同结构的推导),因此文法 (G) 是二义的。
2. 把语句分成两类:
- Matched(已匹配):每个
if 都有对应的 else
- Unmatched(未匹配):存在某个
if 尚未匹配到 else
令开始符号为 (\langle STMT\rangle),给出无二义文法 (G’):
⟨STMT⟩⟨MATCHED⟩⟨UNMATCHED⟩→⟨MATCHED⟩∣⟨UNMATCHED⟩→a:=1∣if condition then ⟨MATCHED⟩ else ⟨MATCHED⟩→if condition then ⟨STMT⟩∣if condition then ⟨MATCHED⟩ else ⟨UNMATCHED⟩
为什么它无二义:在该文法中,else 只能在 (\langle MATCHED\rangle) 的产生式中“闭合”一个 if,并且 (\langle UNMATCHED\rangle) 的结构被设计为:else 必然匹配最近的那个尚未匹配的 if,从而消除 G 的二义性。
同时,它生成的语言与原语言一致:仍然能生成
- 赋值语句
a:=1
if condition then Sif condition then S else S 及其嵌套组合,只是把配对关系固定为唯一解析。
B. 令 Σ=1,2,3,4,C=w∈Σ∗∣in w, the number of 1s equals the number of 2s, and the number of 3s equals the number of 4s。证明 C 不是 CFL。
假设 C 是 CFL,取 s=1p3p2p4p。根据泵引理,可以将 s 分为五部分 uvxyz。由于 ∣vxy∣≤p,则 vxy 不可能同时覆盖 3 和 4,或者 1 和 2,则当重复 v 和 y k (k>0) 次时,必定使得 1-2,3-4 的数量不相等,也就是 uvkxykz∈/C,因此 C 不是 CFL。