[COMPT 0x03] FA→正则表达式/泵引理/上下文无关文法
本节课的主题:
- FA→正则表达式
- 泵引理(The Pumping Lemma)
- 上下文无关文法(CFG)
上一节我们学习了如何将正则表达式转化为 FA,证明了“正则表达式 FA”,这一节我们将学习如何将 DFA 转换为正则表达式,从而证明“FA 正则表达式”。通过学习将 DFA 转化为正则表达式,我们能顺便证明下面这条定理。
📜定理:如果语言 是正则的,那么一定存在某个正则表达式 使得 。
但直接将 DFA 转换为正则表达式是很困难的,所以我们得先引入新概念——GNFA。
GNFA
广义非确定有限状态自动机(Generalized NFA, GNFA)是 NFA 的一种推广,它允许使用正则表达式作为边上的标签,如下图所示。
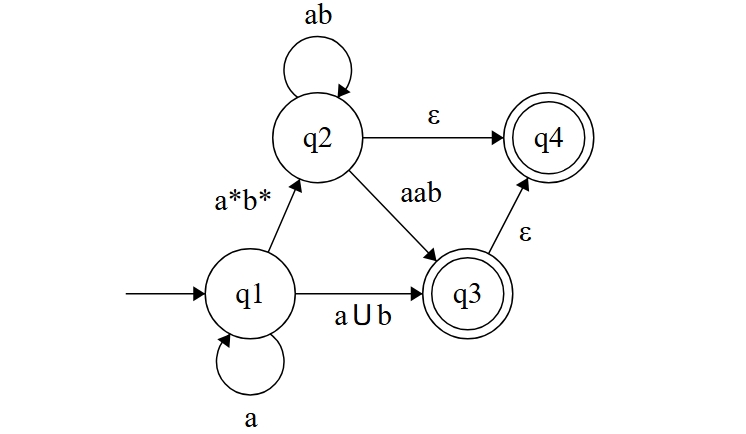
假设输入字符串为 aabbaab。我们从初始状态 q1 开始,边 可以接受 aabb,于是状态变为 ;随后我们走 ,它可以接受 aab,于是状态变为 。GNFA 也是非确定的,同一个输入字符串可能对应多条转移路径,所以和 NFA 一样:只要存在一条路径能抵达接受状态,就认为 GNFA 能接受该字符串。
还记得我们说要把 DFA 转换成正则表达式吗?现在我们要做的不是将 DFA 转换成正则表达式,而是将 GNFA 转换成正则表达式,这其实要更加难!因为 GNFA 是比 DFA 更强大的模型,所以如果能把 GNFA 转换成正则表达式,那么 DFA 也一定能。这就好比是我无法证明我是全班成绩最好的,那我就证明我是全校成绩最好的,这同样能证明前者。
为了方便起见,在正式讲如何把 GNFA 转换成正则表达式之前,我们需要做几个假设来简化转换过程:
- GNFA 只有一个接受状态,并且不能同时为初始状态
- GNFA 中,每个状态之间都应该可以相互转移,甚至应该能转移到自己,但有两个例外:
- 初始状态只能有出边
- 接受状态只能有入边
那么所有 GNFA 都能满足这些假设吗?显然不是,就比如本文一开始展示的 GNFA,它存在两个接受状态,某些状态之间不存在边,初始状态存在指向自己的入边等等,这些都违反了我们的假设。但不用担心,我们有办法对其进行等价变形,使之满足我们的假设。
我们可以新增一个接受状态 ,并让原本的接受状态通过一个 -转移连接到它,然后我们就可以取消原本的接受状态,保证在不改变 GNFA 功能的情况下,使之满足我们的假设。
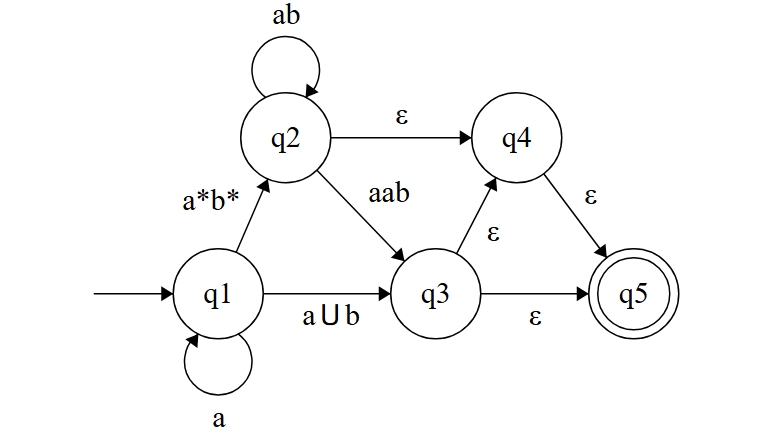
而对于那些不存在的边,例如 , 等,我们可以加上一条 边,表示不可跳转。(下图仅处理了 , 作为示例)
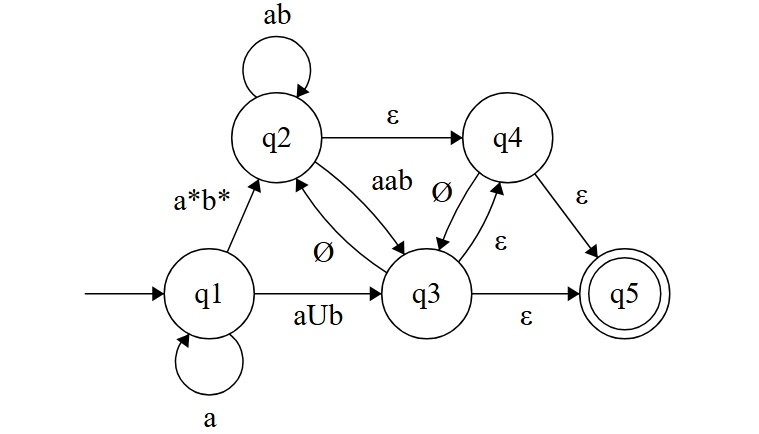
我们还需注意到,初始状态存在一条指向自己的入边,这也是不允许的,我们可以重新设置一个初始状态 ,然后增加一条 的-转移。
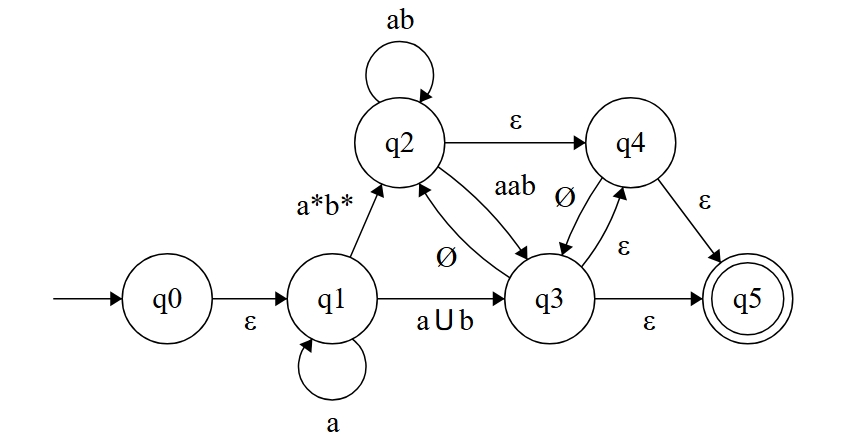
(*注意:上图仅展示了部分状态的处理思路,由于最终的图太过复杂,这里并未完整展示。)
GNFA→正则表达式
在学习将 GNFA 转换为正则表达式之前,我们需要先证明下面这条引理。
📜引理:每一个 GNFA 都有一个与之等价的正则表达式 。
我们将使用归纳推理法证明。首先,我们将证明对于最小的 GNFA(base case),即状态数 的 GNFA,存在一个与之等价的正则表达式 ,这个最小 GNFA 长这样:
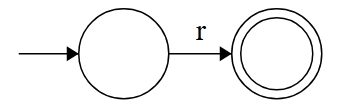
显然,与该 GNFA 等价的正则表达式就为 ,base case 证明完毕。
下一步,我们假设该引理对含有 个状态的 GNFA 都成立,试证明它对含有 个状态的 GNFA 同样成立。证明思路是把 个状态的 GNFA 化简为 个状态,这样就能应用假设了。具体的化简方法如下:
我们首先选择一个要删除的状态,然后将其删去,再修复删除造成的破坏。所谓修复,其实就是构造所有受影响的路径的正则表达式,再使用 运算将它们拼接起来,如下图所示(左边为删除状态 前,右边为删除后)。
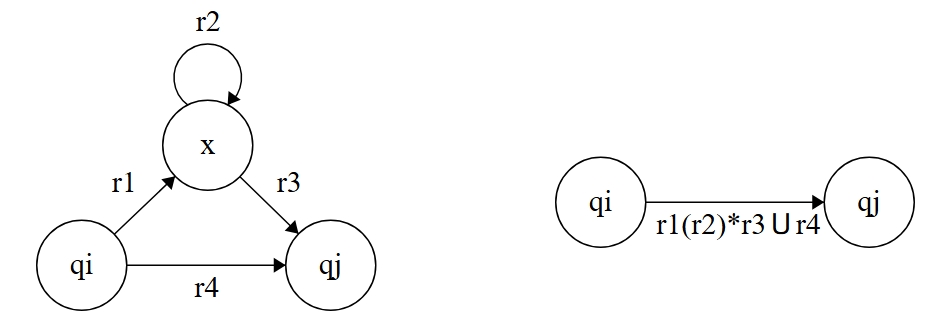
这样,我们就证明了每一个 GNFA 都有一个与之等价的正则表达式 。同时,通过上面的化简方法,我们可以将任意 的 GNFA 转换成最小 GNFA,最后留在那唯一一条转移边上的标签就是其对应的正则表达式,这样就完成了 GNFA→正则表达式的转换。
DFA 和 NFA 作为 GNFA 的特殊类型,如果 GNFA 能被这样转换为正则表达式,DFA 和 NFA 肯定也可以。
至此,我们已经完成了 Lecture 1 中提出的目标——证明 FA 和正则表达式等价。
泵引理
我们此前一直在讨论正则语言,而且我们已经讨论得差不多了,那非正则语言呢?如何证明一个语言是非正则的?
证明一个语言是正则的,我们只需要给出一个对应的 FA;但证明一个语言是非正则的,我们要给出一个证明。下面是两个非正则语言:
直觉上说, 和 肯定都是非正则的,因为如果要构造 FA,我们就必须使用状态来记录 0/1 和 01/10 的数量,但 和 没有对数量进行约束,因此我们将需要无穷的状态,这是不可能的。但如何证明?
📜泵引理:对于任意正则语言 ,都至少存在一个 ,使得如果 并且 ,那么 ,其中:
简单来说,泵引理给出了一个正则语言必须满足的特性,即,对于正则语言 ,必定存在一个“泵长” ,使得当 中的一个字符串 的长度大于等于 时,我们肯定能把它划分为三部分(前两部分的长度加起来不能大于 且中间部分不能为空),当我们把中间那部分重复任意次(这个操作称为“泵”)之后,得到的字符串仍然属于 。
为什么会有这样一条引理?可以这样理解:假设一个 FA 总共有 个状态,而接受字符串()要求它走大于 步,那么其中必定有某些状态被重复走了不止一次(鸽巢原理)。如果这样说还是太过抽象,请把我们讨论的 FA 想象成满足先前假设的 GNFA。我们将这样一个 个状态的 GNFA 化简为 3 个状态,即初始状态,中间状态和接受状态,根据鸽巢原理,中间状态肯定会被反复经过,也就是说,如果我们把这个字符串中能被该中间状态接受的部分重复无数次,也必定可以被该 GNFA 接受。
使用泵引理的关键在于找到一个能“泵”的字符串,下面我们来做几个利用泵引理来证明非正则性的习题。
证明 是非正则的
假设 是正则的。由泵引理,可知至少存在一个泵长 ,当 大于 ,可以把这个字符串划分为满足要求的 ,, 三部分。我们直接令 。由于 ,因此 是 中的一个非空子串。当重复 时,例如 ,显然字符串中 0 的数量必定大于 1,因此 ,违反了泵引理,因此 是非正则的。
证明 ,其中
假设 是正则的。关键是找到一个不满足泵引理的字符串 ,如果找纯 0 的字符串 ,会发现仍可以满足泵引理,但如果混入一个 1,即令 ,由于 ,则 是 中的一个非空子串。当重复 时,例如 ,有 (),显然 。因此 是非正则的。
证明 是非正则的
这道题可以用正则运算的封闭性来做。假设 是正则的。我们在第一题已经证明 是正则的,由 下的封闭性1可知, 也必定是正则的。而 ,在第一题中我们已经证明了 是非正则的,因此 违反了 下的封闭性, 是非正则的。
CFG
接下来我们要学习一种更加强大的模型,它就是上下文无关文法(Context Free Grammar, CFG)。CFG 比 FA 要更加强大,它能做到很多 FA 做不到的事情。但这节课我们只会给它做一个简短的介绍,我们将在下节课详细展开。
一个 CFG 由规则(rules)、变量(variables)、终结符(terminals)和开始变量(start variable)组成。其核心其实是替换规则(Substitution Rules),即,从开始变量开始,按照规则,不断将左边的符号替换成右边的符号,直到字符串中不再存在非终符位置,以此生成字符串。下面展示了一个 CFG :
定义的语言写作 。在这个例子里, 共有三条规则,其开始变量为 ,变量集合为 ,终结符集合为 。规则中的左值只能是非终结符,即普通变量,而右值可以是终结符,也开始是非终结符,或者是两者的组合。
课后题
给定两种语言 和 ,我们定义 和 的 perfect shuffle 为
证明正则语言在 perfect shuffle 操作下的封闭性。
证明封闭性的核心在于构造一个 FA 来识别运算结果。
对于 perfect shuffle 的结果,我们构造一个 DFA,它应该要有能跟踪正则语言 和 对应的 DFA 和 的状态的能力。
我们定义该 DFA 的状态为 ,其中, 和 分别是 和 的状态集; 中的 0 代表下一位字符要给 读,1 代表下一位字符要给 读。初始状态为 ,接受状态为 。
转移函数 定义为(其中, 和 分别是 和 的转移函数):
令 并且
证明 不是正则的。
直接证明有点难,因为其中涉及复杂的进位,但 一看就不满足泵引理,因此我们可以转去考虑一个不带进位的最简单的子语言 ,我们定义
显然, 也满足 的规则,因此 。只要证明 不是正则的,那么 肯定也不是正则的。
假设 是正则的,令 ,根据泵引理,可以将 分为 三部分,由于 ,所以 是 中的非空子串。重复 数次,得到 (),该式显然不成立,不属于 ,因此 不是正则的,进而 也不是正则的。
令 ,对于任意 ,令 为所有倒数第 个位置的字符为 的字符串组成的语言,即 。构造一个具有 个状态的能识别 的 NFA,要求同时给出状态图和形式化描述。
这道题很简单,我们只需要定义初始状态 可以不断接受 和 ,但当每次读到 的时候,可以“猜测”它可能是倒数第 个位置的字符,然后转移,接下来设置 个状态 ,用来记录当前读到哪了,如果走到最后的 时刚刚读完整个字符串则接受,否则拒绝。刚刚好 个状态。可以很轻松画出状态图:
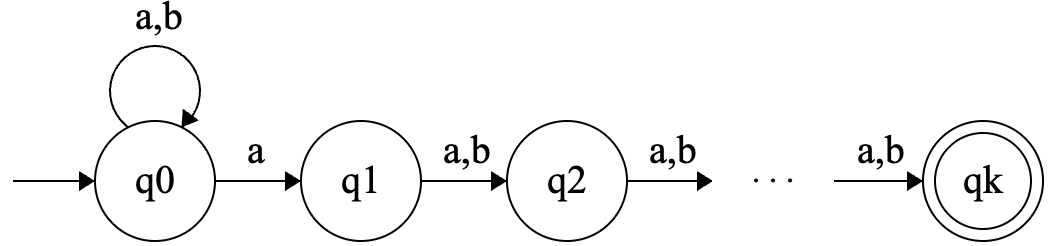
下面是形式化定义:
对于题 中的语言 ,证明凡是状态数小于 的 DFA 都无法识别它。
现在考虑长度为 的字符串 ,即有 。这样的 一共有 种,我们为其编号为 。现在,由于 DFA 的状态数小于 ,由鸽巢原理可知,必定存在两个不同的字符串 和 ,当它们作为输入时,DFA 最终停在同一个状态,即有 。
现在考虑在 和 后面拼接一个长度小于 的后缀 ,构成 和 ,使得 和 的倒数第 个位置上的字符不相同(这一点一定能做到,因为 )。不妨设 的倒数第 位置上的字符现在为 ,而 的倒数第 个位置上的字符为 ,那么就有 ,。
现在将 和 输入 DFA,由于 DFA 在接受完 和 之后停在同一个状态,再加上剩余部分 相同,所以后续行为肯定是相同的,最终肯定仍然停留在同一个状态,导致无法区分 和 ,无法识别 。证毕。
Footnotes
-
我们并没有证明过 下的封闭性,但它显然成立,两个正则语言的交集肯定是正则语言 ↩