[ALDE 0x03] 贪心算法
01 贪心算法
贪心算法是一种思路很朴素的优化算法,其核心思想是在每一步决策时,总是选择当前看起来最有利(局部最优)的选项,希望以此累积得到全局最优解。
但并不是所有算法都能应用贪心算法来求解,一个问题能用贪心算法的前提是其具有贪心选择性质(每步局部最优能导向全局最优)和最优子结构性质(子问题的最优解构成原问题最优解)。
证明贪心算法的正确性通常有 3 个套路:
- 贪心算法保持领先(Greedy algorithm stays ahead):证明贪心算法每一步做的选择都是最优的,所以直到最后一步也是最优的,本质其实是一种归纳法。
- 交换论证(Exchange argument):假设这里存在一个最优算法,然后找到该算法的某一步,对这一步应用贪心,证明换成贪心算法只会使结果更好,或者相同,则说明不存在这种算法,或者这种算法等于贪心。
- 结构性证明(Structural):从问题结构出发考虑,如果问题的解存在某种性质,证明贪心算法总能达成这种性质。
下面本文将以几个问题为例,考虑如何使用贪心算法,需要关注的并不是算法本身,而是最优性的证明,这是考试重点。
02 区间调度问题
区间调度问题的描述是:给定 个工作的开始时间 和结束时间 ,要求选取尽可能多的工作,使得工作区间不会冲突。
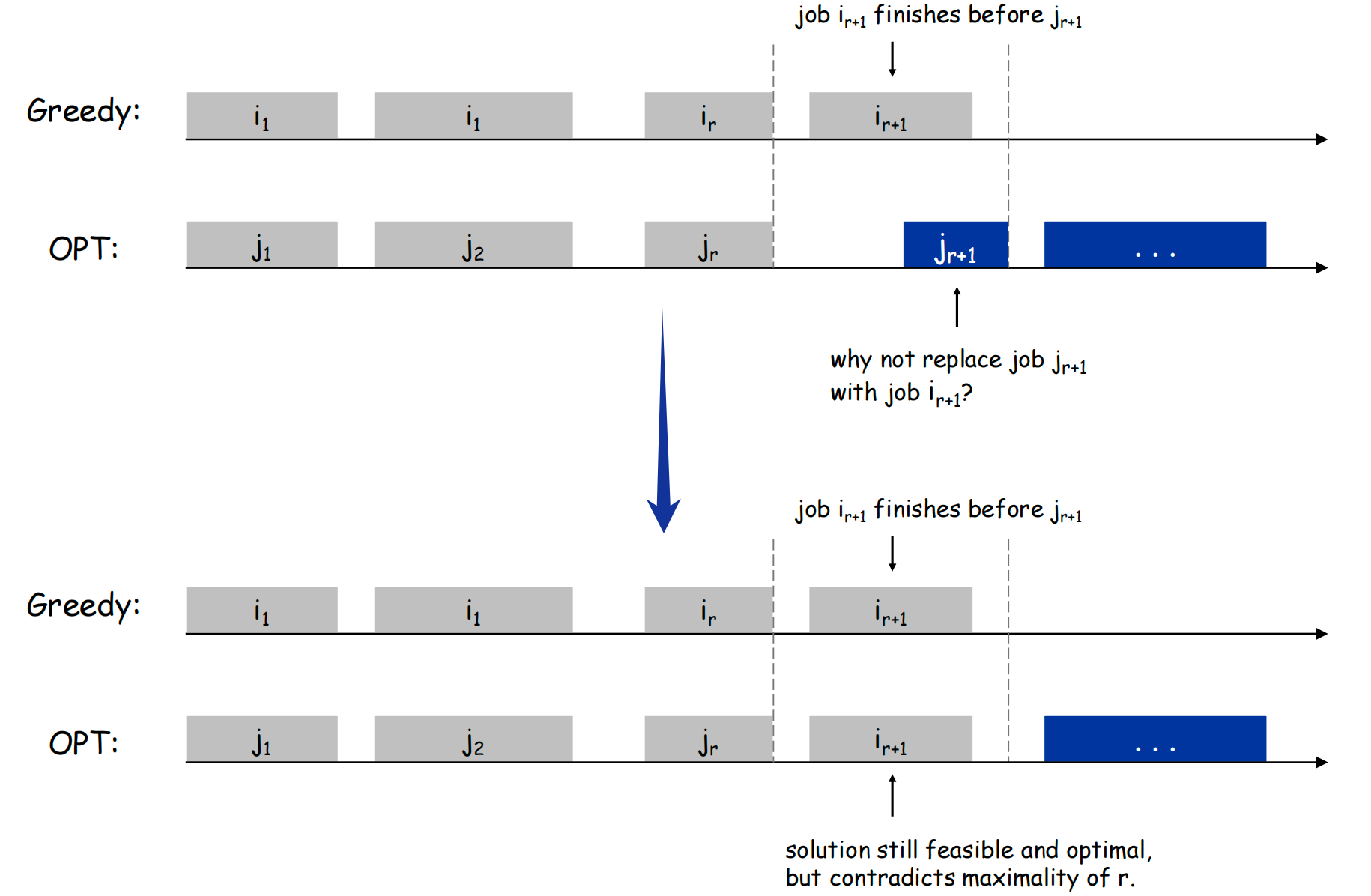
这道题的解法是贪心,但怎么贪?是每次都选最早开始的工作,还是最早结束的工作,亦或是区间最短的工作?这里直接给出答案,是最早结束的工作。我们直接根据每个工作的结束时间进行排序,每次都选排在最前面的,尚未被选取的,不会与已选取的工作产生冲突的工作。这样可以使选出的工作最多。
下面我们使用交换论证来证明贪心算法在这个问题上的正确性:
- 假设存在一个比贪心更好的解法,来看看会发生什么。
- 令贪心给出的解法为 。
- 令最优的解法为 。
- 假设这两种解法在第 个工作的选取上产生了分歧,即存在 ,,,。
- 由于贪心算法每次都选取最早结束的算法,因此 的肯定比 更早结束,那么将 换成 肯定也是可行,并不会改变结果的最优性,这与假设矛盾,因此不存在比贪心更好的解法。
03 区间划分问题
区间划分问题的描述是:给定 个讲座的开始时间 和结束时间 ,问最少需要多少间教室,才能让所有讲座正常召开,不会出现同一时间两个或多个讲座同时占用一间教室的情况。
虽然乍一看这个问题好像很复杂,但其实解法很简单,我们只要找到同一时间内重叠的讲座的最大数量是多少就行了,这个数值就是需要的教室的最少数量。
代码思路如下。我们只需要先按开始时间对所有讲座进行排序,然后遍历每一个讲座,如果能被安排进某间教室就安排进去,否则就增加教室。这种解法的时间复杂度为 ,仅排序时间占大头。
Sort intervals by starting time so that s1 ≤ s2 ≤ ... ≤ sn.
d ← 0 # d is the number of allocated classrooms
for j = 1 to n {
if (lecture j is compatible with some classroom k)
schedule lecture j in classroom k
else
allocate a new classroom d + 1
schedule lecture j in classroom d + 1
d ← d + 1
}下面我们将使用结构性证明贪心算法的最优性。我们注意到,在区间划分问题中,问题的答案具有一个不可突破的下界,即如果某一时刻存在 个讲座重叠,那么最终答案至少为 。下面是证明步骤:
- 令 为贪心算法已分配的教室数量。
- 第 间教室会被需要,肯定是因为存在一个无法被安排进剩余 间教室的讲座,令这个讲座为 。
- 既然讲座是按照开始时间排序的,那么 无法被安排进其余教室,肯定是由开始得比 早的讲座造成的。
- 因此,这里肯定存在 个讲座,它们在 处重合。
- 综上,根据我们观察到的性质,最终答案至少为 ,因此贪心算法的结果已是最优。
04 最小延迟调度问题
最小延迟调度问题的描述是:一种资源一次只能处理一项工作,一共有 项工作需要完成;工作 需要 个单位的处理时间并且必须要在 之前完成;如果 在 时开始处理,它将在 时完成,它对应的延迟为 ;请合理安排所有工作的处理顺序,使得最大延迟 最小。
这里直接给出贪心策略——最早截止时间优先。整体思路较简单,就是排序完后直接线性扫描处理所有工作,如下所示,这里不进行赘述。
Sort n jobs by deadline so that d1 ≤ d2 ≤ … ≤ dn
t ← 0
for j = 1 to n
Assign job j to interval [t, t + tj]
sj ← t, fj ← t + tj
t ← t + tj
output intervals [sj, fj]在证明贪心算法在该问题上的最优性之前,我们先来观察一下解的性质:
- 由于贪心算法是直接线性扫描所有排好序的工作,一个工作完成后就立马安排下一个工作,所以每个工作之间的间隔时间为 0,没有空闲时间。
- 定义逆序对的概念为:工作 和 构成一个逆序对,当且仅当 的截止时间比 的截止时间晚,但是 比 先被处理。在贪心算法的结果中,不存在逆序对。
- 如果工作 和 构成一个逆序对,那么它们俩在调度序列中的位置一定是相邻的。
- 由于逆序对的位置一定相邻,且又没有空闲时间,则交换 和 的位置将会减少逆序对的数量,但不会增加延迟。
下面我们使用交换论证证明贪心算法的最优性:
- 令 为最优的调度方案, 为贪心算法输出的结果。
- 假设 中不存在空闲时间(因为已知贪心结果中没有空闲时间,如果有空闲时间只会比贪心结果更坏)。
- 如果 中没有逆序对,那么 。
- 如果 中有逆序对,令 和 为任意一对相邻的逆序对,已知交换逆序对的位置不会增加延迟,因此只需不停交换 和 的位置,就可以得到 。
- 综上,贪心的结果 就是最优调度方案
05 Dijkstra 算法
Dijkstra 算法的核心思想也是贪心。它在选择下一步要加入到点集 的顶点 时,考虑的永远都是当前 最小的顶点。下面我们将使用归纳法(贪心算法保持领先)证明 Dijkstra 算法的最优性。
首先,我们需要找出一个在算法运行过程中的不变量:在每一轮循环中,对于每个顶点 , 是源点 到 的最小路径长度。下面我们正式开始证明:
- Base case: 时,根本不需要证明,跳过。
- 归纳假设:当 时,Dijkstra 算法仍然是最优的。下面证明当 时 Dijkstra 算法还是最优的。
- 令 为下一个要加入到 的顶点,而 是那条被选中的边。
- 设目前由 Dijkstra 算法计算出的 的最短长度为 ,则 。
- 考虑任意一条 的路径 (如下图所示),可以证明 的长度不可能小于 。
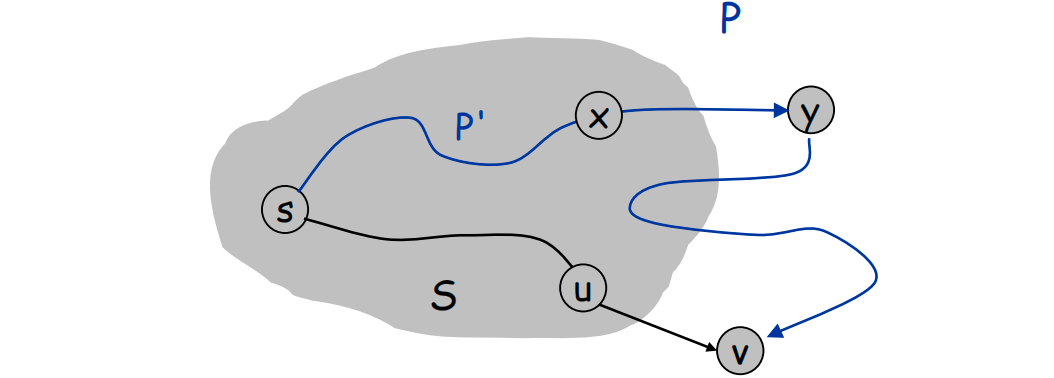
- 假设 是 中离开 的那条路径,并且有 或 ,令 为 中存在于 中的那部分路径,即 。
- 注意此时, 已然大于等于 ,因为:
- 根据假设可知,此时 ,则 。
- 由于 Dijkstra 算法遵循贪心思想,当前它选择了 加入 而不是 ,就说明 。
- 根据 的定义和假设,肯定有 ,因此,综合以上结论,有 。
- 综上所述,不可能存在比 Dijkstra 算法更好的算法。
06 MST
MST 即最小生成树。能求解最小生成树的算法主要有 Prim 算法、Kruskal 算法和 Reverse Delete 算法,这三种算法都蕴含则贪心的思想。
我们将尝试去证明这三种算法的正确性。其实证明它们的正确性,其实就是去证明它们的理论基础:
- 割属性(Cut Property):令 是顶点集合的任意一个子集,令 是恰好只有一个端点在 中的边里,权值最小的一条。那么,必定存在一棵最小生成树包含边 。
- 环属性(Cycle Property):令 是图中的任意一个环,令 是该环中权值最大的边,那么,不存在任何一棵最小生成树包含边 。
下面证明割属性成立,我们使用交换论证,为了方便讨论,我们会假设图中所有边的权值都不相同。
- 假设 不存在于最小生成树 中,看看会发生什么。
- 由 不在 中可以推知 的加入会使得 产生一个环,令构成这个环的边集为 。
- 在割集中,它的一个顶点不在 中,但是 的加入会导致 产生环,说明 中肯定存在另一条边 ,它也在 的割集中(如下图所示)。
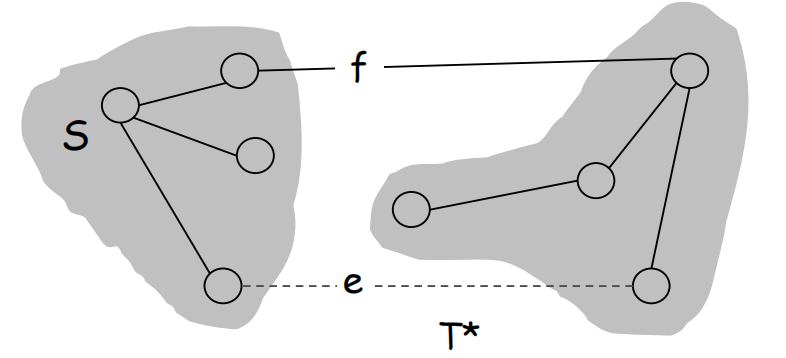
- 那么,如果我们将 中的 换成 ,得到的 肯定也是一棵生成树。
- 由于 ,所以 ,这说明 才是最小生成树,与假设矛盾。
割属性是 Prim 算法的基础。既然已经证明了割属性,那么只要对 Prim 算法的每一步应用割属性就能证明 Prim 算法的正确性了:
- 对于任意一步,令 为当前选取的点集;
- 找到权值最小的割边,根据割属性,这条边肯定是最小生成树的边,将其加入到树 ,因此将它连接的顶点加入到 。
- 重复以上操作,直到所有点都被加入到点集,即 ,最终得到的 肯定是最小生成树。
下面证明环属性成立,我们仍使用交换论证,为了方便讨论,我们继续假设图中所有边的权值都不相同。
- 假设 是最小生成树 中的一条边,看看会发生什么。
- 如果我们从 中删除 , 将不再连通,同时会从 中分割出一个点集 (如下图所示)。
- 由于 在环 中,并且它在 的割集中,因此这里肯定还存在一条边 ,它也在 的割集中(如上图所示)。
- 那么,我们将 中的 换成 ,得到生成树 。
- 由于 是环中权值最大的边,因此 ,这说明 才是最小生成树,与假设矛盾。
环属性和割属性共同组成 Kruskal 算法的理论基础。只要对 Kruskal 算法的每一步应用割属性和环属性就能证明 Kruskal 算法的正确性了:
- 将所有边按权值大小升序排序;
- 情况一:如果将边 加入到 中会产生环,根据环属性, 肯定不是最小生成树的边,应该丢弃 ;
- 情况二:否则,根据割属性, 肯定是最小生成树中的边,将 插入到 中。
- 重复以上步骤,最终得到的树 肯定是最小生成树。
至于 Reverse Delete 算法,其实它就是把 Kruskal 算法反过来。它将所有边按权值降序排序,并不断将当前图中权值最大的边删除,如果删除的边是割,那就跳过。删完后,得到的就是最小生成树。这个过程也是环属性和割属性的应用,跟 Kruskal 算法的证明其实差不多,这里不再赘述。